













CMDB的本质以及它能解决什么问题?
 2020-10-10
2020-10-10  by
by 一、CMDB的本质是什么?
之前很多人问我,CMDB到底是什么?我总是很难回答,因为这个东西有点抽象,你可以说它是一个存储了IT运维对象配置数据和关系的数据库,但总感觉太low。
直到有一天,我看到一部名叫《太空旅客》的电影,这部电影讲述了一群地球人乘坐一艘太空飞船远航到另一个星球殖民,期间飞船发生了故障,一对旅客合力拯救飞船的故事。这艘飞船是这样的:

当发生陨石撞击后,电影迅速切换到总控中心的监控画面:
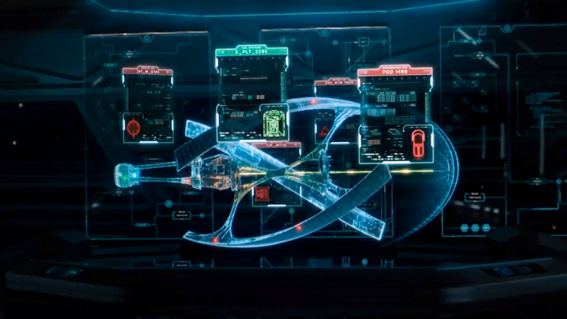
当时我忽然有一种被电击的感觉,这不就是CMDB嘛!
不过那时对这玩意也没有一个标准叫法。就觉得这不仅仅是一个好看的飞船画面,它包含了一些更深层的东西。直到近两年,随着IoT产业的发展,一个新词频繁的出现:数字孪生。听到这个词后,我脑海中忽然又浮现出太空旅客的飞船画面,同时蹦出四个字母:CMDB。
这里简单介绍一下什么是“数字孪生”?
所谓“数字孪生”,是指以数字化方式为现实对象创建虚拟模型,以模拟其在现实环境中的行为以及和其他对象的交互关系。这里说的现实对象包括设备、建筑、园区、软件系统、业务流程等现实存在的物理或逻辑上的事物。
数字孪生由美国国防部提出,用于航空航天飞行器的健康维护与保障。在数字空间建立真实飞行器的模型,并通过传感器实现与飞行器真实状态完全同步,这样每次飞行后,根据现有情况和过往载荷,及时分析评估是否需要维修,能否承受下次的任务载荷等。
数字孪生一般有四个特征:
同质化
指现实对象和虚拟对象之间的数据不存在脱节或知识鸿沟
连接性
指通过传感器实现数据从现实对象到虚拟对象的传递
可编程
指对虚拟对象的编程可影响到现实对象,以提升现实对象的可用性和性能
数字跟踪
对现实对象或虚拟对象的任何操作都有数据日志,以便于跟踪
而CMDB也完美的符合上面四个特征:
同质化
指CMDB数据模型描述IT环境的能力。这里主要考验配置模型的设计粒度。理论上,当CI模型的粒度足够细,属性足够多,CI就和现实运维对象完全一致了。但实际上需要平衡成本和效益。合理的做法是,我们的配置模型应具备同质化描述IT环境的能力,但在实施时不能一步到位,要根据需求和成本一点点做;
连接性
指CMDB数据应该与IT环境是一致的,IT环境变化,CMDB数据也要自动变化(在线CMDB);
可编程
对CI的编程可触发对现实IT环境的调整(比如重启一个CI,现实服务器就重启了),但这里需要实现CMDB与自动化平台、流程管控平台的紧密结合;
数字跟踪
对现实对象的任何操作都有日志记录,这里指流程数据沉淀。
上面四个特征中,非常重要的是同质化和连接性,是CMDB成功的基石。
这里的同质化说的就是配置模型。配置模型的好坏决定了CMDB描述IT环境的基本能力。比如在某金融客户项目中,我们在客户领导和技术专家的设计成果基础上,融合了行业优秀的实践,形成了具备客户个性化特色的配置模型。总体上,IT资源被划分为三个大的层次:应用层、基础资源层、基础设施层。每一层都有特定的CI分类和关系,如下图:
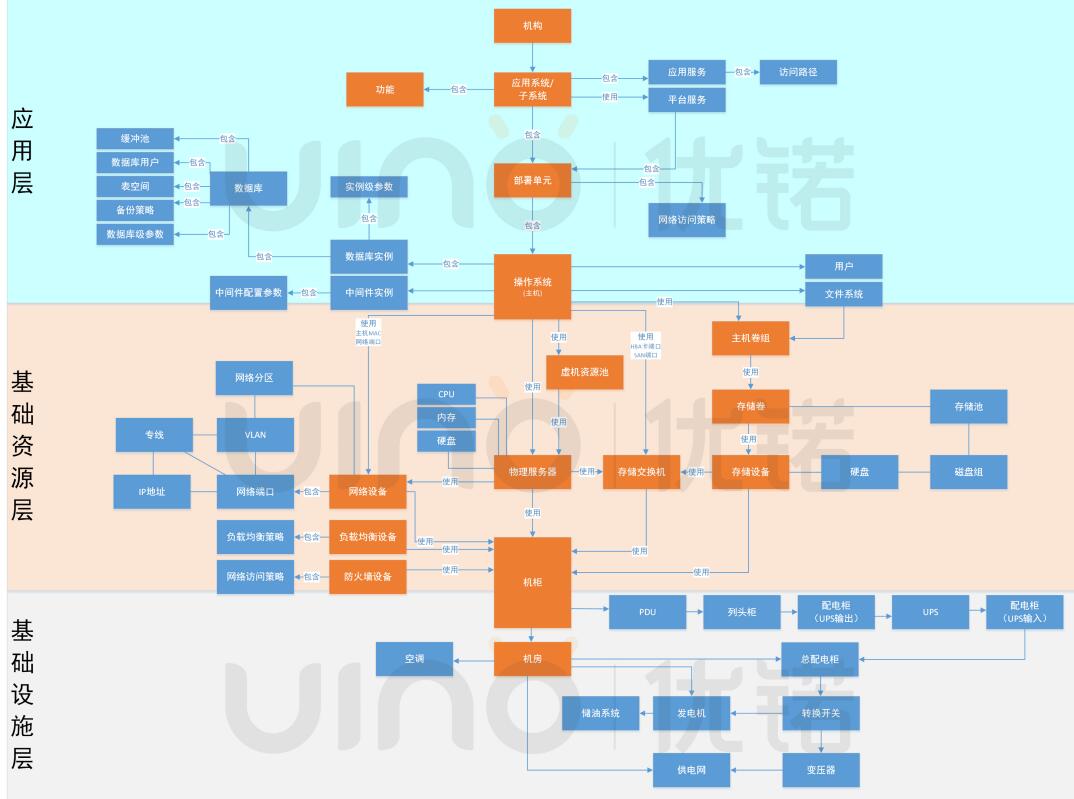
上述CI分类有两种颜色,橙色和蓝色,分别对应核心模型和领域模型:
1.核心模型会被广泛使用,所以要优先落地并重点保障数据质量。核心模型要小而美,要稳定,因为对其修改可能影响范围比较大。
2.领域模型主要在各技术岗内部使用,跨部门的数据共享需求不高,可由各技术管理岗自主建设和维护。这样的好处是各岗位可根据自身管理需求灵活调整数据模型和内容,提升大家使用CMDB的积极性。
配置模型相当于CMDB的基因,它决定了CMDB同质化描述现实IT环境的基本能力。但我们要也要清楚,基因并不是静态的,它是不断进化的,所以在设计配置模型时,也不需要过度纠结,大方向正确即可,形成阶段性成果后尽快投入实战检验。
有了好的配置模型,相当于CMDB有了不错的基因,接下来要解决数据的连接线问题,通过不断健身让CMDB保持生命的活力。所谓连接性,就是数据要在线。如果数据不在线,完全依靠人工维护是不靠谱的,过几天就不准了。从行业实践看,CMDB的数据连接性(或称在线率)要超过60%才能活下来。

可是怎么解决数据在线率问题? 物联网好办,弄一些传感器实时上报数据就行了。但是IT环境比较麻烦,主要有三个方面的挑战:
1.大部分IT对象不会主动上报数据,需要探针扫描,这就需要开通账号权限和网络访问策略,会涉及一些安全风险和性能隐患;
2.IT环境老变,新对象往往因为各种权限或网络隔离原因而无法扫描到,需要通过运营来持续提升自动发现覆盖率,所以涉及持续的成本投入;
3.另外还有很多管理信息(责任人、重要级别等)是无法通过扫描获得的。
所以,CMDB的连接性不是上一个自动发现工具,然后打一个响指就搞定了,如果真这么简单,CMDB的失败率就不至于这么高。

保障CMDB数据在线率是一个系统性工程,需要流程、CMDB、自动化平台、自动发现平台四者相互配合:

就自动发现本身而言,应该多策略、多方案并举。我们知道,自动发现本身除了实施成本外,还会涉及安全风险(开权限和网络访问策略)、性能风险(对被发现对象的性能可能有微小影响)和持续运营投入(确保新增对象被及时发现),有没有更好的方案来规避这些问题?
举一个实际的例子:我们之前完成了DB自动发现测试,能够发现数据库实例名、库名、表空间、用户等信息,基本满足DBA组的需求。但要成功的发现这些DB,首先需要使用NMAP工具对全网扫描,根据端口特征识别哪些服务器上有DB,然后再用一个专用DB账号执行命令获得数据。NMAP全网扫描和专用DB账号这两个事情就和安全部门掰扯了很长时间。后来DBA告诉我们,数据库有一个专门的性能分析工具,里面有所有需要自动发现的数据。我们为什么不直接做一个集成接口,将数据拉过来就行了?所以在实施自动发现时,要先调研目前是否已有更好的替代工具,我们的目的是提升数据连接性,要寻找风险和成本小、见效快的办法,自动发现只是其中一种技术手段,不要把手段当成目的。
二、CMDB要解决什么问题?
CMDB能解决什么问题,网上有很多分享文章都有讲,大家可以自行搜索了解。由于每个地方管理现状、痛点不太一样,所以对CMDB的具体用法也不一样。在某金融客户的实际项目中,基于客户IT运维管理现状,在CMDB建设初期到底能解决什么问题?经过前期的初步探讨,我们觉得在建设初期可以考虑下面四个场景(注意,这些场景不需要有多么宏伟,初期可能只是解决一些小问题,并在此过程中持续优化,让CMDB逐步成长、成熟):
1.网络访问策略查询
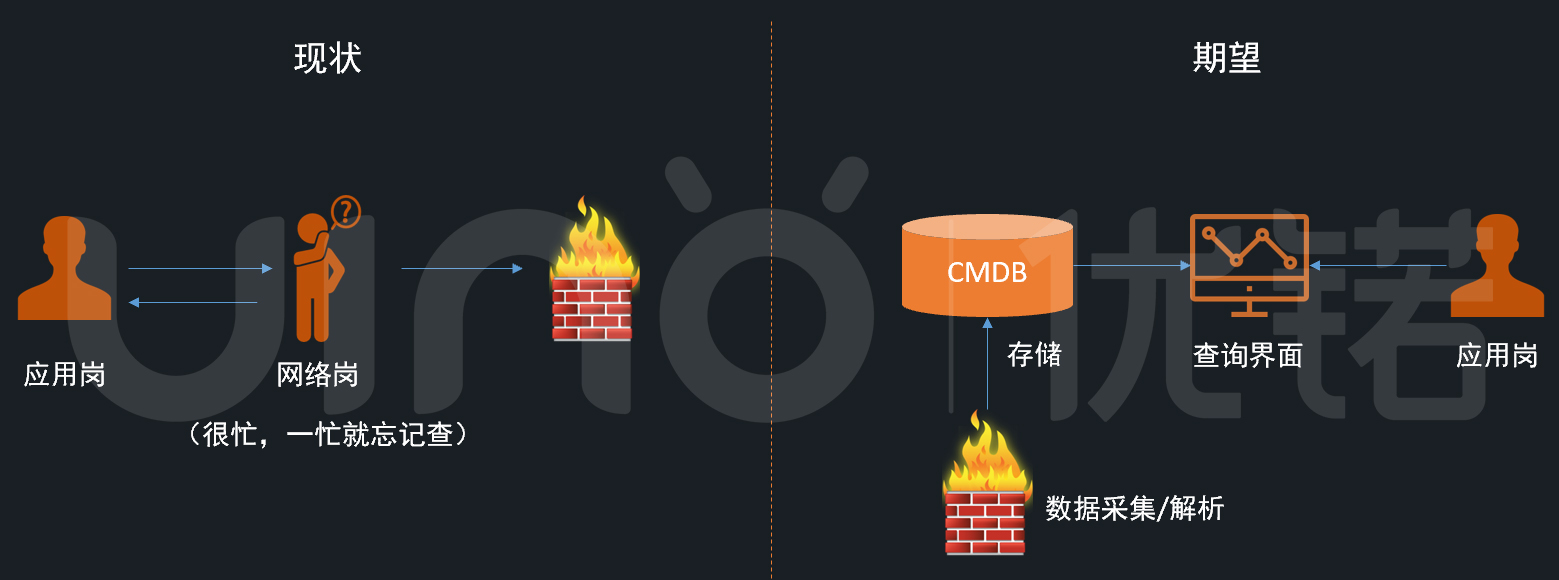
网络岗客户告诉我们,应用岗经常找他们问某些IP的网络访问策略,这让网络岗很头疼,因为网络岗自己也不是特别清楚所有IP的访问策略,往往需要登到防火墙上查一下。这种事情虽然小,但架不住多啊,很干扰正常的网络运维工作。有没有可能自动抓取防火墙策略,讲数据解析出来入库到CMDB中,这样应用岗直接去CMDB查就是了,不用老是麻烦网络岗。
2.文件系统告警通知
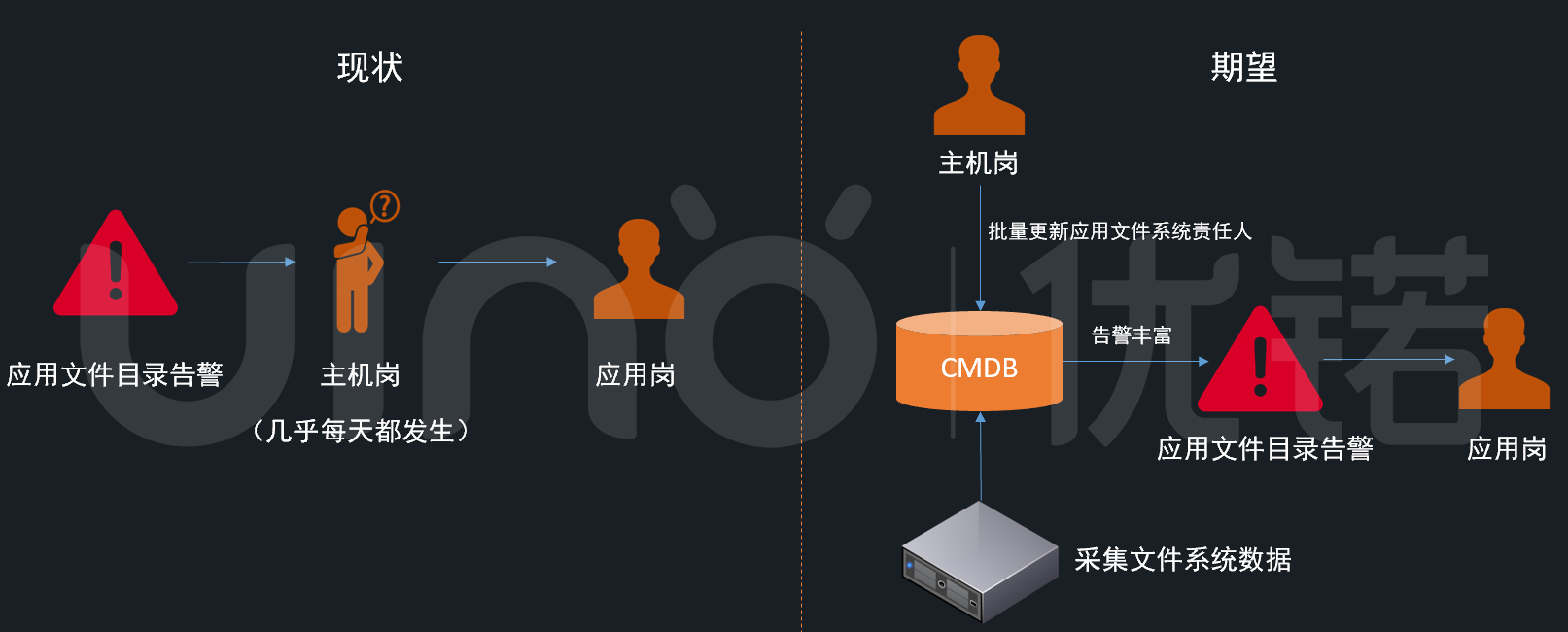
主机岗客户告诉我们,现在很多文件系统告警本来应该是应用岗处理。但因为监控系统无法识别文件系统的负责人,所以一股脑儿都报给主机岗了。这就给主机岗增加了额外的信息传递成本,还增加了告警处理时间。能否通过CMDB,将文件系统责任人信息丰富给告警,让告警及时传递给正确的人员?
3.服务请求数字化
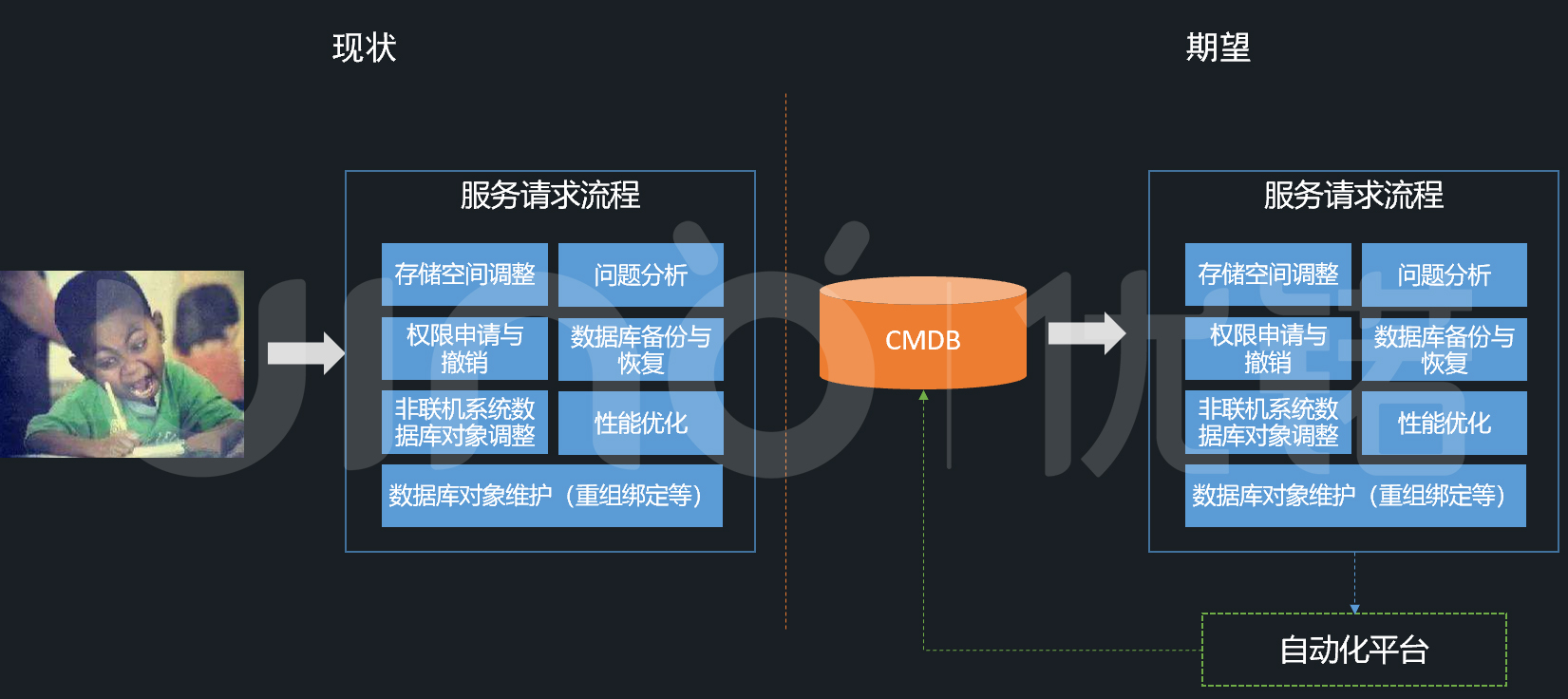
所有IT资源的申请、安装部署、迁移、卸载都要走服务请求流程。我们发现,很多配置信息都会在流程中声明,但却没有和CMDB联动,这会导致流程操作记录无法与CI关联上,也就无法从CI角度回溯历史工单。我们希望提升流程的数字化水平,将IT资源配置信息自动沉淀到CMDB中。
4.监控覆盖率
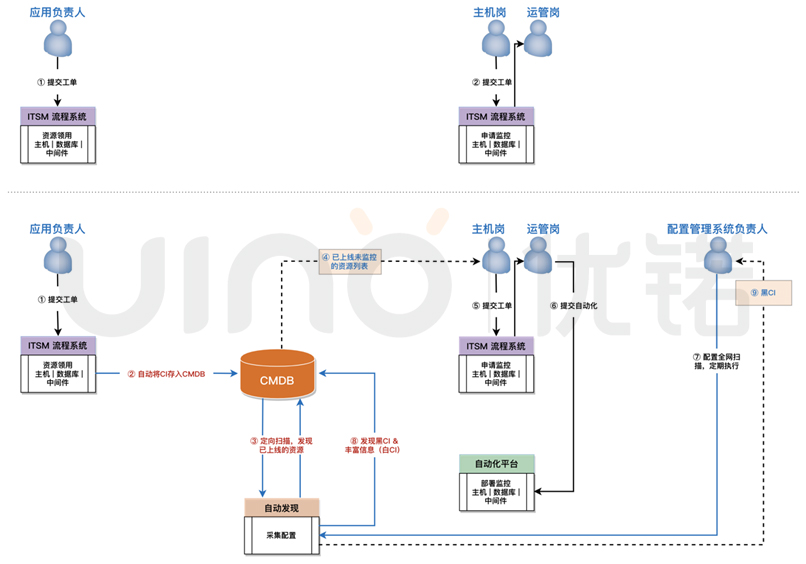
监控是另一个有趣的场景。目前的情况是,用户通过服务请求完成资源申请和部署后,主机岗、应用岗和数据库岗还需要针对新部署的资源提交监控申请,然后运管岗负责监控部署工作。这就有可能因为各种原因导致监控遗漏。而这种遗漏很难发现,因为运管岗并不清楚目前IT环境中到底有哪些服务器、数据库和中间件,根本无从统计监控覆盖率。能否通过CMDB解决这个隐患?比如让CMDB定期输出一份清单,告诉监控系统新增了多少IT资源,更进一步,未来是否可以将CMDB中新增的IT资源自动同步给自动化平台,实现监控的自动部署?
上述四个场景是我们阶段性调研的结果,未来可能有更多场景。不过,我们会发现上面四个场景都有一个共性,就是都在利用CMDB解决跨团队、跨工具的数据共享问题。这是CMDB的核心定位。
热门标签
热门文章
 12.4K 13.8K 15.6K 14.9K
12.4K 13.8K 15.6K 14.9K


